Главной целью создания и разработки многочисленных типов параллельных машин, о которых мы говорили в прошлой статье, это скорость. Суперкомпьютеры и многопроцессорные системы могут и должны делать все быстрее! Давайте постараемся расчитать, насколько быстрее.
Логично подумать, что если один процессор выполняет работу за n секунд, то четыре процессора потратят n/4 секунд. Понятие «фактор ускорения» (“speedup factor”) это отношение времени, которое тратит на выполнение работы один процессор к времени, которое тратит на эту же работу многопроцессорная система.
S(p) = T<sub>s</sub> / T<sub>p</sub>
Для расчета важно использовать самый оптимальный Ts, то есть лучший из возможных не-параллельных алгоритмов.
Теперь плохие новости: у этого ускорения есть лимит. Называется он Amdahl’s Law (Закон Амдала) и вот его суть: так выглядит какая-либо задача на обычной однопроцессорной системе:

Все время выполнения — знакомое уже нам Ts, состоит из той части, которую можно распределить на несколько процессоров (распараллелить) — (1-f)Ts, и той части, что распараллелить нельзя (серийная) — fTs.
Как будет выглядеть схема той же задачи для нескольких процессоров?
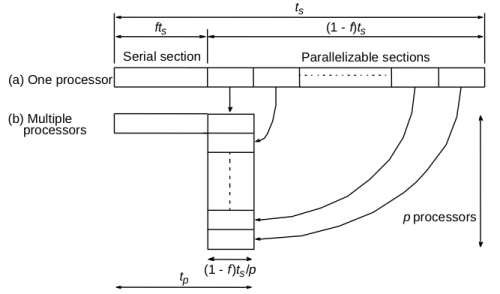
Теперь общее время выполнения Tp состоит из серийного времени и максимального из тех, что мы распределили на несколько процессоров (выполняются они все одновременно, но ждать нужно самого медленного). Для простоты допустим, что все они занимают одинаковое время.
Фактор ускорения расчитывается по формуле:
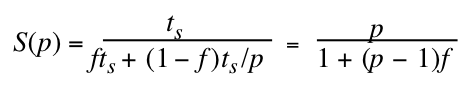
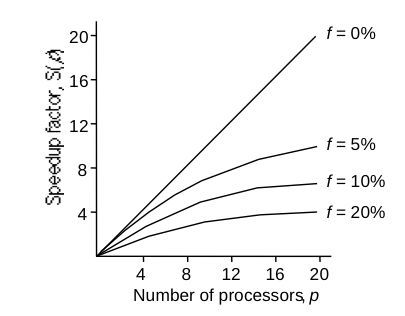
То есть все зависит от того, какой кусок программы мы сможем распараллелить (f в процентах означает количество серийного кода). Если f=0%, то есть абсолютно весь код распараллелен (чего практически не может быть), то чем больше процессоров мы задействуем, тем быстрее будет выполнена задача, и соотношение будет линейное: хотим в 10 раз быстрее — используем десять процессоров, хотим в миллион раз быстрее — закупаем миллион процессоров. Но вот стоит оставить 5% серийного кода, а 95% распараллелить, то фактор ускорения будет равен 20 и выше никак не прыгнуть. Даже если закупим к тому миллиону еще миллион процессоров, то программа все равно будет выполняться в 20 раз быстрее. Вот как этот грустный факт выглядит на графике с примерами разных процентов f:
Получается, что самое важное в вопросе эффективности параллельного кода — это хороший дизайн самого алгоритма. Каждая деталь может сильно повлиять на расширяемость: если сейчас алгоритм нормально использует ресурсы четырехядерного процессора, то возможно больше 8 ядер он нормально использовать не сможет, и тогда через год программу нужно будет писать заново — ведь вместо количества транзисторов теперь каждые полгода увеличивается количество ядер!
Чтобы написать хороший параллельный алгоритм, нужно вникнуть в суть проблемы и подумать, как его можно разделить на отдельные независимые (в идеале) части, чтобы все они выполнялись параллельно на разных процессорах. Посмотрим на примере довольно ёмкой задачи умножения матрицы А на вектор b. Результат будет записан в вектор y, который по размеру идентичен вектору b. Чтобы получить первое значение вектора y, нужно умножить первую строку матрицы на вектор b, чтобы получить второе значение y — вторую строку на b, и так далее. Получается, каждый элемент вектора y можно считать независимо от других, то есть параллельно.
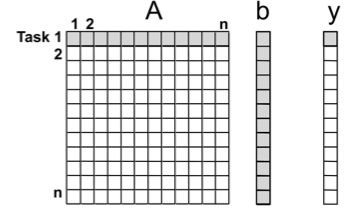
Размер каждой такой задачи один и тот же — все строки A имеют одинаковый размер (пока не касаемся таких деталей, как плотность матрицы — возможно, в ней много нулей, но предположим, что это не сильно влияет на время выполнения). Нет никаких зависимостей между задачами, и все задачи используют один и тот же b.
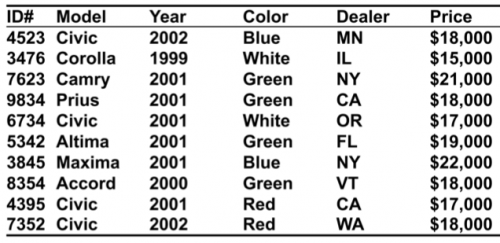
Вот другой пример — запрос в базу данных:
MODEL = “CIVIC” AND YEAR=2001 AND (COLOR=”GREEN” OR COLOR=”WHITE”);
Запрос пытается получить все зеленые или белые Цивики 2001 года из такой базы:
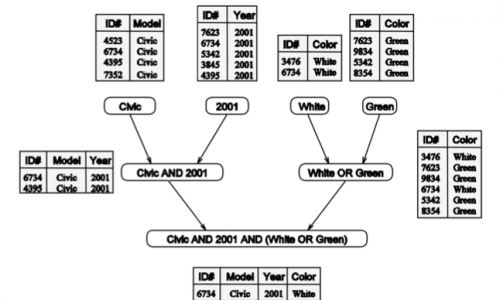
Такую задачу можно разложить на три части: один процессор будет формировать таблицу все Цивиков 2001 года, другой процессор будет формировать таблицу всех белых и зеленых машин (эти два запроса могут идти параллельно), после чего результат join’а этих двух таблиц и будет ответом.
Можно изменить структуру запроса, что может повлиять на параллелизацию
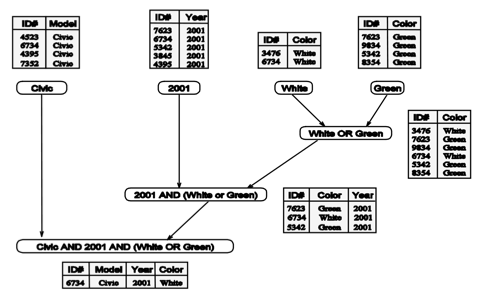
Разделение задачи на части для последующего распределения этих частей на разные процессоры называется декомпозицией. Умножение матрицы на вектор это пример декомпозиции результата задачи: результат (вектор y) был разделен на несколько независимых частей и каждая расчитывалась отдельно от другой. То же самое можно сделать и с перемножением матриц:
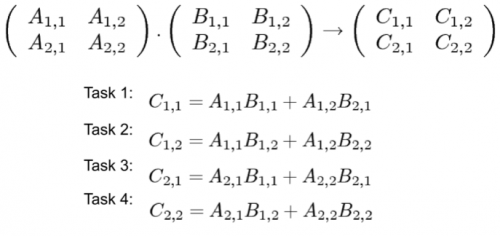
Наша первая параллельная программа
Для написания нашей первой параллельной программы мы будем использовать Cilk. Это язык программирования, который по сути является С с удобными инструментами для параллелизации и синхронизации задач. Cilk был разработан в MIT в 1994 году, был бесплатным и свободным, но к 2006 году стал коммерциализироваться, стал поддерживать С++, а год назад был куплен с потрохами компанией Intel, которой, конечно же, выгодно иметь хороший язык программирования для многоядерных систем: они ведь саим такие системы и производят. Я не уверен, как можно получить компилятор бесплатно, в нашем университете есть академическая версия для студентов (разработчик Cilk хороший друг профессора), поэтому прошу меня извинить, если вы не сможете найти его. Но поискать, я считаю, стоит, потому что Cilk жутко прост и удобен! Не сравнить с Pthreads. Все, что нам нужно знать, чтобы начать программировать, это три ключевых слова: cilk, spawn и sync.
Лучше всего начать с примера, поэтому вот вам любимая всеми рекурсивная задача — числа Фибоначи — на Си:
int fib (int n){
if (n<2) return n;
else {
int x, y;
x = fib (n-1);
y = fib (n-2);
return (x+y);
}
}А вот та же программа на Cilk:
cilk int fib (int n){
if (n<2) return n;
else {
int x, y;
x = spawn fib (n-1);
y = spawn fib (n-2);
sync;
return (x+y);
}
}Заметили разницу? ,)
Ключевое слово cilk используется для указания функции. Самыми главными являются слова spawn и sync. Spawn ставится перед вызовом функции, которую мы хотим запустить на другом ядре, а sync ждет окончания выполнения всех вызванных ранее spawn’ами функций. То есть строчка
x=spawn fib(n-1);запускается на другом ядре, и сразу выполняется строчка y=spawn fib(n-2). Перед тем, как вернуть результат (return (x+y)) нужно дождаться окончания выполнения, иначе в переменных x и y не будет правильных значений. Это делает команда sync — как и понятно из названия.
Правда, легко?
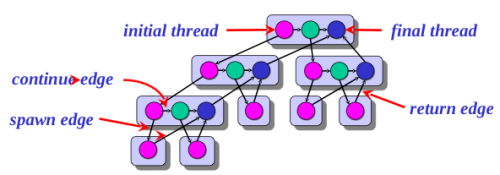
Такая программа хоршенько загрузит множество ядер! Вот как выглядит схема работы этого алгоритма для n=4:
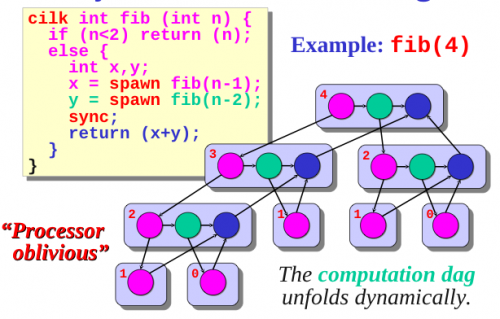
Цвета подсветки кода соответствуют цветам узлов графа. Каждый уровень графа выполняется одновременно, то есть первый вызов для n=4 вызывает две функции — для 3 и 2, они в свою очередь — для 2 и 1 и для 1 и 0 соответственно.